


Patrickův newsletter #73: 🥳 Před branami všeobecné umělé inteligence...?

Dobrý den!
Vítejte u únorového dílu Patrickova newsletteru. A řekněme si to narovinu: bude především o umělé inteligenci. Tam, kde se zastavíme u něčeho jiného, jako jsou čipy a procesory, bude to zase kvůli tomu, že jde o čipy pro umělou inteligenci 😎
O čem bude dnešní newsletter?
OpenAI Sora je nový LLM model, který převádí text na video
Google má nový model Gemini Pro 1.5 s rozšířením kontextu (a co to vlastně je???)
Všichni shánějí peníze na čipy - a kdo na co a od koho?
Reklamní vsuvka: pořádám workshopy o AI ve firmách
Ukazuji firmám, jakou změnu pro ně představuje AI. Můj workshop AI ve firmách je společná interaktivní SWOT analýza toho, jak na vaši firmu dopadne umělá inteligence. Pojďme se nad tím společně zamyslet…
(Web jsem samozřejmě nechal vygenerovat AI 🤖)

OpenAI Sora je nový model, který převádí text na video
Minulý týden se pokusil Google ohromit celý svět novým posunem stran umělé inteligence nazvaným Gemini 1.5. Jenže společnost OpenAI byla nachystána a aby přerazila jakýkoliv dojem, že existuje ještě někdo jiný, kdo by svět umělé inteligence posouval, okamžitě uvolnila informace o novém AI nástroji nazvaném Sora, který umí převádět textové zadání do videa. Překotnost uvolnění informace je viditelná na první pohled. Je patrné, že OpenAI měla všechny tiskové informace připravené předem, presskity odladěné, ale samotný model Sora pro veřejnost neuvolnila, vydala z něj jen výstupy. Pravděpodobně jde o nějaký druh PR zápolení s Googlem, protože naprosto stejně (řekneme si později) postupoval i Google: informace vydal, model neuvolnil.
Co je Sora? Velký jazykový model, který umí z textového zadání vytvořit hyperrealistická, až minutová videa. Videa jsou opravdu perfektní, alespoň ta uvolněná. Ale podrobností o tom, jak se k nim nástroj společnosti OpenAI dohrabal, je pramálo (techspec je maximálně vágní). Což dost handikapuje oznámení. Tak především se vlastně neví, odkud se vzala tréninková data - tedy jaká videa OpenAI více či méně vykradla.
Srdcem systému Sora je difuzní transformátor, vizionářský model inspirovaný velkými jazykovými modely (LLM), který je určen ke zpracování vizuálních dat. Jedná se o komprimaci videodat do časoprostorových políček, podobných tokenům, kterým rozumí LLM, které jsou poté vycvičeny a znovu sestaveny do nových videosekvencí s vysokým rozlišením. Tento inovativní přístup nejen zjednodušuje složitý svět video dat, ale také se přizpůsobuje možnostem zpracování transformátorů, což znamená významný skok od manuální přesnosti Unreal Engine k intuitivním, daty řízeným poznatkům systému Sora.

A o čem se v souvislosti s modelem Sora debatuje v USA? Jak dopadne tento nástroj na filmový průmysl. Podle mě zatím nijak zásadně a naopak vytvoří nový trh, potenciál má ale ničivý.
Vyzkoušet to zatím nemůžete, ale nějaká vzorová videa jsou tady...
Mimochodem, když jsme u těch videí, k čemu se to dá použít? Služba Neiro umožní vytvořit váš vlastní avatar a pak jej nechat odvyprávět text dodaný přes webové rozhraní či API. Já jsem použil předpřipraveného avatara, nechal jej načíst začátek dalšího odstavce a obrazově jsem to umístil do galerie Villa Pellé, kde probíhá výstava obrazů Adolfa Lachmana Lachland, kterou mimochodem doporučuji navštívit. Video zde.
Google Gemini Pro 1.5 a rozšíření kontextu
Google se v poslední době hodně snaží a s umělou inteligencí posouvá. Před dvěma týdny vydal model Ultra 1.0, minulý týden pak model Gemini Pro 1.5. Budeme si muset trochu udělat pořádek v Google AI modelech, ale nebojte, ještě to chvilku počká, protože Google je nejdříve oznamuje a veřejné uvolnění mu trvá, tím spíše pro Českou republiku. Co je ale důležité: Google opouští značku Bard a své nové LLM modely označuje jako Gemini.
A teď k novému modelu Gemini Pro 1.5. Ten nemá mít tolik parametrů, tedy takový rozsah, jako model Gemini Ultra oznámený před týdnem, hlavní výhodou Gemini Pro 1.5 má být velikost kontextového okna. Ta má být až deset milionů tokenů. A to jsou dvě věty, u kterých se zastavíme, abychom si to vysvětlili.
Tak za prvé: co je to token? Token je významové slovo v rámci LLM modelu. Odpovídá zhruba lidskému slovu, jde ale o číselnou reprezentaci slova s rozlišením jeho významu. Pokud může mít jedno stejně písmenně zapsatelné slovo více významů, má také více tokenů. Slovo hra má jeden token, pokud je divadelní, jeden, pokud je počítačová a další, pokud je to dětská hra. Velké jazykové modely se tak vyrovnávají s nejednoznačností lidského jazyka, kterou převádějí na matematickou jednoznačnost.
Za druhé, co je to kontextové okno? To je v zásadě délka "promptu", tedy dotazu či úkolu a všech příslušných dat, které zadáváte jako dotaz jazykovému modelu. Starší modely v dávnověku (předloni a vloni) uměly pracovat s rozsahem desítek, maximálně stovek tokenů kontextu. Situaci významně změnil model Claude od společnosti Anthropic loni v létě, kdy nabídl nejprve 100 000 tokenů a později ještě dvojnásobek, pak GPT Turbo zvedl standard na 128k tokenů.
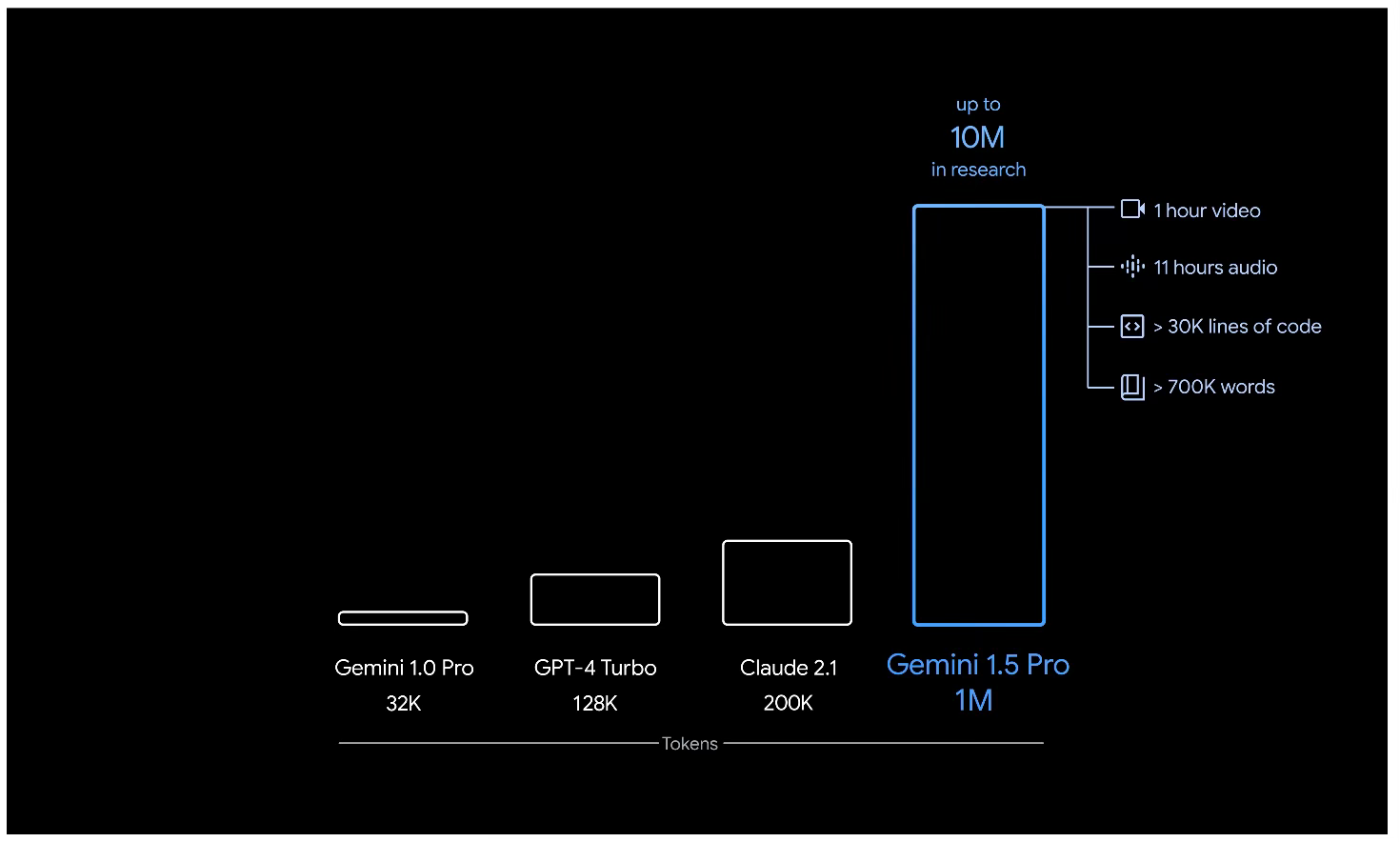
Proč je to důležité? Protože délka kontextu rozhoduje o tom, kolik dat můžete předat do AI v rámci "dotazu". Všechno ostatní je totiž zapomenuto nebo zmateno. Jasně, na větu "vymysli vtip obsahující čecha, maďara a slováka" si vystačíte s velmi malou délkou kontextu, jenže promptem je potřeba předávat knihy nebo i celá videa u multimodálních modelů. A jen delší kontext umožňuje předat PDF knihy do AI nebo dokonce video a nechat jej AI zpracovat jinak, než přes natrénování. Do AI tak můžete nacpat i velmi dlouhá data a nechat je nějak zpracovat, například zanalyzovat. A to je hodně důležitý první moment.
Jsme na předpolí AGI?
Druhý důležitý moment dlouhého kontextu je, že takto vložená data jsou předpokladem pro univerzální umělou inteligenci (AGI). Ta se díky takto vkládaným podkladům může naučit vykonávat nové úkoly, které dosud neuměla. Příkladem může být experiment s Gemini Pro, které mohlo překládat texty z pramálo používaného jazyka jen poté, co mu byla dána mluvnice dotyčného jazyka. Dlužno ovšem dodat, že Gemini zřejmě tento kontext nezahrnuje do jazykového modelu, může ho použít pouze tady a teď. Naopak ChatGPT zavedl zanášení dat z promptů do historie, ovšem zřejmě jde jen o jednu z vrstvev v transformátoru, která při průchodu promptu do LLM obohatí prompt o historický kontext, například o to, že chcete, aby se vždy GPT vyjadřovalo žertovně.
Podstatnou informací ovšem je, že rozsáhlejší kontextové okno zpřístupňuje Google respektive DeepMind zatím jen některým uživatelům a nejsou úplně přesvědčivé podklady o tom, jak to funguje, takže na širší zhodnocení je příliš brzy. Zatím jen počítejme s tím, že se blízká na lepší časy!
Mixture of Experts
Tohle je podstatná novinka z modelu Gemini Pro, která stojí za jeho radikálním zlepšením: funkce nazvaná Mixture of Experts (MoE).
Architektura Mixture of Experts (MoE) představuje pokročilý přístup k navrhování a trénování hlubokých neuronových sítí. Mixture of Experts modely jsou založeny na ideji, že místo jedné velké neuronové sítě, která se snaží naučit se všechny aspekty úkolu, je efektivnější použít soubor menších "expertních" modelů, kde každý expert se specializuje na určitou část úkolu. Výsledný model poté dynamicky vybírá a kombinuje výstupy těchto expertů na základě vstupních dat.
Jak architektura MoE funguje?
Rozdělení na Expertní Modely: V MoE architektuře je úkol nebo dataset rozdělen mezi různé expertní modely. Každý z těchto modelů je trénován na specifické části úlohy nebo dat, díky čemuž se stává "expertem" v určité oblasti.
Vrstva Brány čili Gateway: Na začátku modelu stojí vrstva zvaná "gateway" nebo také "dispatcher", která rozhoduje, jaké expertní modely budou pro daný vstup použity. Tato vrstva analyzuje vstupní data a na základě toho dynamicky směruje data k relevantním "expertům".
Kombinace Výstupů: Po zpracování vstupních dat expertními modely se výstupy těchto modelů kombinují. Tato kombinace se obvykle provádí pomocí váhování, kde větší váha je přiřazena výstupům od expertů, které systém považuje za nejrelevantnější pro daný vstup.
Učení a Optimalizace: Celý systém je trénován end-to-end, což znamená, že se učí nejen samotné expertní modely, ale také mechanismus, který rozhoduje, jak data rozdělit mezi experty a jak kombinovat jejich výstupy.
Škálovatelnost a Efektivita: Jednou z hlavních výhod MoE je, že umožňuje modelu škálovat efektivněji, protože není nutné, aby každý expert byl aktivní pro každý vstup. To znamená, že lze trénovat mnohem větší modely, aniž by došlo k exponenciálnímu nárůstu výpočetních nároků.
Podobnou technologii údajně používá i GPT-4 nebo opensource LLM Mistral. MoE je zatím přítomné jen v Gemini Pro, zajímavé by bylo sledovat, co udělá, až/pokud bude nasazen v Gemini Ultra.
Všichni shánějí peníze na čipy
Prudký nárůst poptávce po AI také přinesl nebývalou poptávko po čipech. Nvidia, dnešní leader v čipech pro trénování AI, nestíhá vyrábět a dodávat. Meta investuje 10 miliard dolarů do nákupu čipů na trénink AI v průběhu roku, jedna čipová sestava Nvidia H100 stojí kolem milionu korun, takže utrácení do AI čipů jde hodně rychle. Sam Altman shání sto miliard dolarů na to, aby mohl pro OpenAI vyrábět čipy. Peníze na čipy shání kdekdo.
Projekt Izanagi je nový čipový podnik zakladatele společnosti Softbank Masajoši Sana. Projekt má konkurovat Nvidii v oblasti procesorů umělé inteligence. Projekt se snaží doplnit společnost Arm Holdings společnosti Softbank, která navrhuje architektury procesorů. Není jasné, zda procesory umělé inteligence navržené v rámci projektu Izanagi budou vycházet z technologií vyvinutých společností Arm. Projekt může ovlivnit plány společnosti Arm na vytvoření referenčních návrhů čipů pro různé pracovní zátěže. Je oddělen od jakékoli spolupráce s OpenAI. Podstatné je, že Masajoši San do projektu chce sehnat investici kolem 100 miliard dolarů - a je to člověk, kterému se to pravděpodobně podaří.
(Na okraj, Izanagi je ústřední božstvo japonského šintoismu. Izanagi společně se svou sestrou a zároveň družkou Izanami měli dokončit stvoření Země. Trochu nafoukané jméno projektu, proto to zmiňuju.)
Je otázka, kolik místa pro čipové firmy tu ještě je. Pokud se bavíme o těchto firmách, mějme na paměti, že to obnáší návrháře čipů, ne jejich skutečné výrobce. Vyrábět je pravděpodobně bude TSMC, které jediné dnes disponuje dostatečnou výrobní základnou. A v takovém případě je otázka, zda by se Softbanku nevyplatilo koupit třeba Cerebras zabývající se výrobou cloudových a trénovacích ASICů a nebo Tenstorrent zaměřený na ASICy pro datacentra pro AI. Ale abychom si to řekli jasně: co Masajoši dělá, dobře dělá a nevsázel bych vlastní peníze proti jeho názoru…
Přečtěte si článek na Forbesu o čipových fimách v roce 2024.
Mezitím rekordních hodnot dosahuje nákup vybavení na výrobu polovodičů do Číny. Čína intenzivně nakupuje jakékoliv vybavení, jak nové, které je možné přes americké sankce sehnat, tak staré linky, které stále mohou dobře sloužit pro výrobu automotive elektroniky. Čínský dovoz litografických strojů na výrobu čipů dosáhl v roce 2023 rekordní výše více než 7 miliard USD a oproti předchozímu roku vzrostl o více než 270 %. Prudce rostou exporty jak nizozemského ASML do Číny, tak japonského Tokyo Elektron. Čína se tak poněkud brání americkému čipovému embargu, které dopadlo především na špičkové AI čipy a na zařízení pro jejich výrobu.
Probíhající válka o polovodiče však poukazuje na stupňující se cyklus nákladného obchodního konfliktu velmocí, který se stal dominantním prvkem hospodářské politiky. Budování nadbytečných kapacit k posílení dodavatelských řetězců má značné náklady, stejně jako přerušení nebo přesměrování bilaterálního obchodu mezi dvěma největšími ekonomikami světa. Obchodní válka mezi USA a Čínou se v průběhu času jen stupňovala a úroveň výdajů na průmyslovou politiku a intenzita obchodních omezení, které jsou v současnosti uplatňovány, by byly ještě před deseti lety nemyslitelné. Obě země v současné době platí tyto náklady a teprve se ukáže, zda některá z nich bude schopna z vítězství vytěžit výhody.
Jednohubky na závěr
📲 WAVE AI je mobilní aplikace, kterou hodně používám a platím za ni pětistovku za měsíc bez reptání. Dělá mi zápisy z porad. Prostě pustíte aplikaci a ona vám udělá po poradě zápis. Když se vám nelíbí, tak jí řeknete, že ho má předělat se zaměřením na finanční rovinu projektu atd. Zatím jen pro iOS.
✈️ Co brání leteckému průmyslu ve výrobě nových komerčních letadel? článek.
📔 Squad je zajímavý AI nástroj pro stavbu produktové strategie. Služba.
👩🔬 SciSpace je služba pro analyzování a výzkumy, skvělé, když se do něčeho chcete ponořit. Služba.
Tak a to je pro tentokráte všechno.
Vše nejlepší přeje
Patrick Zandl
PS: Tento newsletter byl rozeslán na 3051 adres.
Wave AI je dobrý, díky!
je to cvrkot v tom AI světě... just announced 👇👇👇
https://blog.google/technology/developers/gemma-open-models/