


#93 📈 Žádný exponenciální růst schopností AI zatím není
Že každých 7 měsíců AI zdvojnásobí svoje schopnosti? To byla hodně zkratkovitá interpretace jedné studie. Podíváme se, jak je to ve skutečnosti...

Chtělo by se dodat, že zatím. Podrobněji si situaci rozebereme později v newsletteru, nyní se pojďme podívat, co nového je v technickém světě.
Na to se podíváme později, nyní si zrekapitulujme novinky:
🇪🇸⚡️ Ve Španělsku (a Portugalsku) měli v pondělí 28.4.2025 blackout elektřiny
Byl jsem zrovna na cestě na konferenci tajemníků měst a obcí, událost jsem pokryl, ale hned z kraje jsem naletěl na článek Reuters, kde to vysvětlovali vcelku věrohodně, ale blbě, počasím. Situace je složitější a ještě stále není celá rozkrytá, takže si vývoj událostí zaznamenávám zde na Marigoldovi v jednom chronologickém článku. Článek průběžně aktualizuji.
Jak určit polohu pořízení fotografie pomocí ChatGPT o3? - s pár lidmi jsme se vyblbli a vydestilovali jsme postup, jak co nejlépe využít model o3 k určení místa pořízení fotografie.
Čínské AI posiluje, vlastní GPU nadohled. A další dubnové novinky v AI aplikacích
Meta v maléru - svědectví bývalé šéfky Facebooku o tajných dohodách s Čínou
aktualizoval jsem pro vás přehled LLM - které k čemu máte použít. Můj tip: přes web vždy používat ChatGPT o3, je fakt skvělý. Přes API sahejte po Google Gemini 2.5 Pro, bývá v akci zdarma, například na Openrouteru.
OpenAI vydalo větší oficiální zprávu k přehnaně lichotícímu modelu 4o. Model byl doslova patolízalský. Jak se to stalo? OpenAI vyhodnocovala odezvu u více kandidátských modelů, v souhrnu ty změny ale způsobily patolízalství.
Amazon představil svůj nejnovější LLM Nova Premier, který má být úžasný. Nicméně jsem ho zatím netestoval, motivace k tomu, seznamovat se s další rodinou modelů je pramalá… čím přesvědčí?
Suno vydal model 4.5 pro AI komponování hudby a songů. Je to zase výrazně lepší, než půl roku stará čtyřka. Navíc nabízí editaci! Připravil jsem vám několik verzí zhudebněné Jobovy noci od Hrubína, abyste to mohli posoudit. Lajkněte, která se vám líbí nejvíc!
Před 25 lety Clintonova administrativa oznámila rozhodnutí vypnout záměrnou chybu v civilních signálech GPS. Tím umožnila vývoj GPS od armádní do všudypřítomné globální služby, kterou máme dnes. Díky za to!
Kdo jste se smáli tomu, že americké akcie po nástupu Trumpa vymazaly miliardy ze svých hodnot, tak už je všechno zase zpět... To neříká nic o Trumpovi, jen to, že argument akciemi není nejlepší...
Na internetu se objevují doporučení zeptat se vašecho ChatGPT na věci, které využijí všechny chaty, které jste s GPT vedli. Něco ve stylu “na základě našich konverzací mi doporuč” - pozor na to, ChatGPT v Česku ještě nezpřístupnilo funkcionalitu, kdy se může podívat i do obsahu jiných chatů, než toho aktuálního. V Česku tyto prompty dávají halucinační výsledky (leda byste už tu funkci měli).
🔎 Boj o AI vyhledávání
Letošek nebude jen rokem agentů, ale také rokem tlaku na vyhledávání na internetu. Vždycky mě překvapovalo, jak si Google snadno nechal vzít svoje prvenství v AI - vždyť všechny podstatné objevy se udály do roku 2020 pod jeho taktovkou. Dnes hraje třetí housle, nedá se však Satya Nadellovi upřít, že chytil vítr a jede nekompromisně ve směru vítězství. Nové modely 2.5 jsou fakt skvělé a solí to všude, kde mohou. Jenže nyní se dostávají pod tlak ve vyhledávání. Perplexity nabízí vyhledávání přes AI již dlouho, ale je malé, Google neohrožuje. OpenAI má miliardu uživatelů měsíčně, to je už jiné. OpenAI zařadilo před nějakou dobou vyhledávání a nyní jej rozšiřuje mezi stále více uživatelů. Zatím mám přes AI jen pár přístupů, zatímco z Google stovku denně, ale poroste to.
Novým hráčem je Anthropic. Claude zpřístupnilo vyhledávání na webu pro všechny placené tarify celosvětově (už ne jen v US). Pro každodenní úkoly Claude spouští rychlé vyhledávání. Pro složitější otázky prozkoumává více zdrojů, včetně Google Workspace. Jak se to projeví? Dejme tomu chvíli.
Google jen chvíli před tím zpřístupnil vyhledávací "AI Mode" pro americké uživatele ze svého vyhledávání. Čili do svého vyhledávání přidává výsledky generované AI. Zatím ovšem jen v USA, detailněji na blogu Google. Co AI Mode zvládá?
• Dlouhé, složité otázky
• Následné otázky
• Lokální + produktové vyhledávání
• Doporučení v reálném čase
Google také spustil bezplatný přístup k Gemini 2.5 Pro v Gemini Canvas (pracovním editoru). A je to moc dobré! Gemini Canvas byste měli vyzkoušet, je to pracovní editor podobný Google Docs, ve kterém tvoříte spolu s AI - podobně jako v ChatGPT Canvas.
🛒 ChatGPT jako nákupní asistent
Tento týden byla tiše představena nová funkce, která proměnila ChatGPT z asistenta pro zodpovídání otázek na nákupního průvodce s obrázkovými karusely (stejně jako vyhledávání Google), recenzemi, cenami a odkazy na nákup. Tato funkce je k dispozici v GPT-4o a GPT-4o-mini pro všechny, tedy pro uživatele Pro, Plus, Free a dokonce i pro odhlášené uživatele. Zavedení trvalo jen několik dní, není třeba zakládat účet ani instalovat aplikaci. Jednoduchost a rychlost jsou na prvním místě
Zadejte „sluchátka s potlačením hluku do 200 dolarů“ nebo „kostýmy pro mé dva psy“ a ChatGPT vám nejen odpoví, ale také vám ukáže, co si můžete koupit. Aby bylo jasno, nejde o reklamu. OpenAI trvá na tom, že se nejedná o placené umístění a že (zatím) nebere žádné provize. Výsledky jsou získávány pomocí strukturovaných metadat získaných z webových stránek obchodníků prostřednictvím OAI-SearchBot, což je bot, který prochází veřejné webové stránky, ale netrénuje modely. Jinými slovy, jedná se o verzi vyhledávacího indexu od OpenAI. Obchodníci se mohou přihlásit (nebo odhlásit) a dokonce sledovat provoz z ChatGPT pomocí UTM tagů.
Při spuštění je zaměření produktu úzké, ale strategické: móda, krása, domácí potřeby a elektronika.
Vyzkoušejte, zadejte v ChatGPT něco, co budí dojem, že hledáte výrobky z těchto sekcí a uvidíte, co vám ukáže...
📈 Exponenciální růst schopností AI? Zatím ne!
Byl jsem jeden z mála, kdo neokomentoval tento graf METR, v němž křivka schopností AI letí strmě vzhůru, když dělá kýženou hokejku, exponenciálu. Přitom já vám nějakou dobu tvrdím, že k průlomu v AI nedochází. Jak s tímto tvrzením sedí tato "hokejka"?
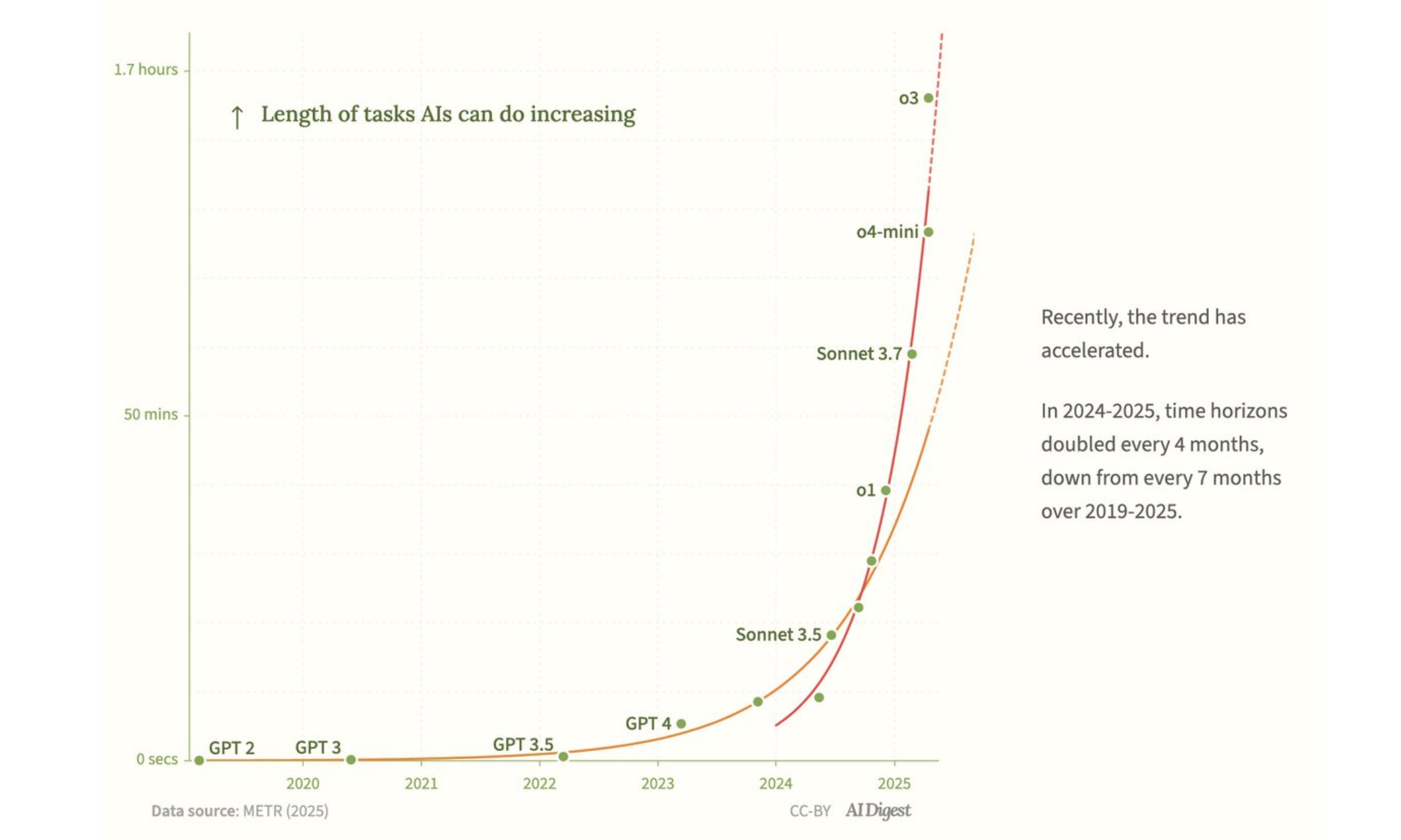
Tady je třeba vrátit se k tomu, co studie znamená. Tak především, tento graf se v původní studii METR z března 2025 neobjevuje, to je jeho aktualizace o nové dubnové modely. Původní graf končí starou verzí Sonnet 3.7. Až v dubnu jej METR na Twitteru aktualizoval s informací, že "o3 může být nad trendovou linkou", z čehož AI Digest udělal tento graf, který už převzaly i Financial Times, velké čínské weby i česká média a interpretovaly jej jako "každých sedm měsíců zdvojnásobí AI své schopnosti". Což by ukazovalo na obdobu Moorova zákona, kterou jsem já popíral.
Ve skutečnosti zpráva METR nic takového neříká. Poskytuje určité vodítko, ale to vodítko nelze vytrhávat z kontextu. Aby zpráva mohla měřit komplexní úlohy, rozhodla se problém zploštit na to, že říká, jaké lidem nejdéle trvající úlohy zvládne daný model AI s padesátiprocentní úspěšností. METR vytvořil respekt budící sestavu úloh, z niž většinu nezveřejnil, aby zabránil jejich natrénování - u těch určil, kolik trvají lidem a změřil, zda při jejich realizaci dosáhne konkrétní LLM alespoň poloviční úspěšnosti vyřešení. To je zajímavé číslo, ale má několik problémů.
Především: testován byl jen vývoj software
Tak za prvé METR se soustředil na úlohy z oblasti vývoje software, například zde je jedno velmi dobře popsané zadání:
Úkolem je implementovat funkce pro zpracování plateb a zabránění duplicitním transakcím, které přicházejí asynchronně z různých časových pásem a měn. Dvě platby musí být spárovány na základě fuzzy pravidel, jako je časový rozdíl mezi časovými pásmy a vícestupňové převody měn.
METR nechal tuto úlohu naprogramovat externistu a ten ji (s použitím knihoven) dokončil za 23 hodin a 30 minut. Tento čas se vzal jako benchmark a tato úloha má stanovenou složitost na tento čas. METR nenechal všechny úlohy programovat větší množství lidí, to udělal jen u těch kratších a dokonce i u těch složitějších jen provedl odhady na bázi vývojářské metodiky. Test zjišťuje, zda v průměru (přes mnoho - průměrně 5 - pokusů a úloh) model dosahuje více jak 50 % úspěchu. Ten průměr je definován pomocí logistického modelu napříč různě dlouhými úlohami, nikoli jen prostým „půlka běhů jedné úlohy musí projít“ - ale to už je pro nás detail.
Podstatou problému ale není to, jestli by člověk tuto úlohu zvládl dříve či později či jak moc je vypovídající jeden pokus programátora na definicu času v metodice METR - to je v podstatě jedno, to jen posouvá křivku doleva nebo doprava.
Není totiž ani jisté, že úloha, kterou METR ohodnotí na dvojnásobek času, je skutečně dvojnásobně složitější. To už by mělo vliv na tvar křivky. METR tento problém do jisté míry řeší tím, že úloh má více a pro vykreslení křivky používá regresi, takže úlohy, u kterých by špatně odhadnul časovou náročnost na člověka, se zprůměrují a křivka nakonec nebude trpět takovou deformací.
Podstatný problém je, že úlohy se týkají pouze vývoje software, na který je dnešní AI velmi detailně trénována. Vývoj SW je dnes největší doména použití AI a většina moderních modelů se předhání užitečností v podpoře vývoje software. Jenže to není jediná skupina úloh, které lidé řeší. Vůbec tu nejsou matematické úlohy - například tradiční úloha "kolik písmen r je ve slově strawberry" je pořád pro řadu modelů těžký oříšek. LLM nejsou zdaleka tak silná v logických či slovních, imaginativních úlohách, ale ani v právních a nebo třeba neumí vzít obrázek oblečení a převést jej do střihu oblečení.
METR tedy vzdal disciplínu, ve které je dnes AI nejsilnější - a tam konstatoval, že se prodlužuje významně délka úloh, které AI zvládne samostatně vyřešit. Jenže si to popišme lidskými slovy, co nám METR říká:
METR zjistil, že po třech letech soustředěného úsilí největších a nejbohatších firem v oboru, jako je Google, Microsoft, Anthropic či OpenAI jsou dnešní nejlepší modely AI jako o3 nebo Sonnet 3.7 schopné řešit programátorské úkoly ve složitosti kolem dvou hodin. Úkoly, které by lidskému programátorovy trvaly déle, zatím spíše řešit neumí(*). Čili úloha, jak pomocí AI nahradit programátory, která dotyčné firmy trápila velmi silně (tvoří velkou část jejich nákladů), je dnes stále vyřešena jen na velmi juniorní úrovni. Úlohy o dvouhodinovém rozsahu nejsou zase tak nic moc (**), to znamená, že se za takovým programátorem musí 4x denně stavit jeho šéf na poradu a zkontrolovat, jak pracuje.
První hvězdičku jsem si tam musel metodicky nahodit, protože úlohy o délce 2 hodin vyřeší model o3 s pravděpodobností 50 %, což ale fakticky znamená, že ho pustíte cca 3x a zřejmě to dá, což s ohledem na to, že to bude řešit pár minut, není takový problém.
Druhou hvězdičku musím dát s ohledem na kvalitu zadání. METR podává velmi přesné zadání úkolu, které nenechává mnoho prostoru pro výzkum. Prostě sednete a kódujete, nad ničím nebádáte, vše je jasně zadáno. To nebývá v Česku tak obvyklý způsob zadávání práce.
Nezjistili jsme vůbec nic, jak by vám AI pomohlo v jiných profesích. Na to nebyly žádné úlohy vytvořeny a po pravdě si řekněme, že v jiných profesích, než vývoj software, žádná takto soustředěná angažovanost firem není.
Lidský svět je mnohovrstevnatý. Můžete být skvělý programátor, ale jako člověk stojíte za houby. To, jaký jste programátor, neříká také nic o tom, jak jste schopný řešit jiné typy úloh a ani nic o tom, jak moc se zvládnete dále rozvíjet.
Co tedy z testu METR můžeme opravdu usuzovat?
Silnou korelaci má relativní pořadí modelů - je to opravdu dobře stanovené a prokázané pořadí modelů pro řešení softwarových úloh.
Spíše orientační je složitost či spíše délka úloh, které model zvládne s 50 % pravděpodobnosti - ta složitost záleží na přesnosti prvotního odhadu.
Velmi diskutabilní je tvrzení o trendu zlepšování se AI na řešení vývojářských úloh, kdy ke zdvojnásobení nastává neustále rychleji. METR do log‑grafu vynesl, jak dlouhé lidské úlohy každý model zvládá s 50 % úspěšností, a na tyto body položil přímku. Sklon vychází tak, že hodnota na ose Y se v průměru zdvojnásobí každých 212 dní. Jenže těch měření je velmi málo a jsou zatížena značnou chybou. Dokud nemáte další měření (a menší chybu), nemůžete s jistotou tvrdit, že růst zrychlil. Přesně v této situaci je METR: trend vypadá exponenciálně; poslední dva body (o3 a o4-mini) naznačují možnou akceleraci, ale kvůli ± 19 % „rozmazání“ dat to ještě není statisticky průkazné.
Nelze také usuzovat nic o tom, zda se dotyčné LLM vyplatí jako náhrada programátora, protože do dat se nezaznamenávalo, jak dlouho trvalo naprogramování té úlohy pomocí AI, nákladové srovnání tu tedy není.
A odvozovat z grafu tvrzení typu „AI zvládne všechny hodinové kognitivní úlohy do X měsíců“ je zcela mimo. Studie pokrývá téměř výhradně software‑inženýrství. Chybí multimodální, sociální či fyzicky orientované úkoly. Jakákoliv extrapolace mimo SW je tedy zcela neodúvodněná.
Nejsem sám, kdo se k obecné interpretaci jinak precizní zprávy METR staví skepticky. Kromě časopisu Nature si podobně povzdech Gary Marcus či Cole Wyeth. Také Steve Newman konstatuje, že poslední dva body (o3 a o4-mini) leží nad trendem, ale uvnitř itervalu šumu, takže na potvrzení akcelerace je třeba počkat. Zvi Mowshowitz (blog Straight Line on a Graph) připomíná, že extrapolace na měsíční úlohy předpokládá neměnný exponent, což je v historii inženýrských trendů vzácné. Také poukazuje na fakt, že exponenciála může zpomalit, jakmile se vyčerpá „nízko visící ovoce“. Chcete‑li si udělat co nejširší obrázek o diskusi, doporučuji začít Marcusem (je ostrý, ale čtivý), pak Steve Newman a jeho střízlivé technické detaily...
Čili AGI ani Moorův zákon pro AI zatím není potvrzen. A podle mne ani na dohled.
Chcete-li moji předpověď pro dalších deset let, dopadne to s LLM podobně, jako s lidmi. Několik málo modelů dosáhne vysokého A-IQ a za velkých nákladů budou schopni dělat velmi pokročilé věci, ale budou mít své limity a zádrhele - podobně, jako jsou psychické vady a deprese u geniálních lidí. Například vysokou míru halucinací (o3 ji má!). Levné a méně inteligentní modely se budou hodit na rutinní úlohy. Dalších deset let strávíme především propojováním jednotlivých software, LLM, agentů a světa lidí.
Technodrobky na závěr
Apple: firma ohlásila výnosy 95,4 mld. USD za fiskální 2Q 2025 (+5 % r/r), přičemž služby vytvořily nový rekord 26,6 mld. USD a už třetí rok po sobě táhnou růst marží. iPhony však dál ztrácejí dech v Číně – dodávky tam meziročně klesly o ≈9 %, což se odrazilo i ve 14 % poklesu tržního podílu. Do toho se komplikují výsledky iPhone v USA kvůli Trumpovým tarifům, Apple zvažuje výrobu pro USA v Indii (bez cel!), ale zatím to není jednoduché...
Velkou změnou je i nová politika Apple App Storu: po soudním sporu s Epicem smí vývojáři v USA vkládat do aplikací tlačítka a odkazy na vlastní platební brány, aniž by odváděli provizi Applu – zatím ale jen jeden „jasně označený“ odkaz na aplikaci. Apple z toho má velký průšvih, protože se ukázalo, že před soudem lhal o tom, jak App Store je zpoplatněn a z toho bude ještě mrzení.
Alphabet (Google) - První čtvrtletí přineslo tržby 90,2 mld. USD (+12 % r/r). YouTube reklama vyskočila na 8,9 mld. USD, a díky AI‑poháněným formátům má průměrné CPM nejvyšší od roku 2021. Google zároveň oznámil, že jeho Gemini AI zpřístupní – v režimu „Family Link“ – dětem mladším 13 let; rodiče dostanou při prvním použití upozornění a mohou službu zablokovat.
Meta - Reality Labs prochází dalším zeštíhlením: podle Reuters bylo propuštěno přes 100 lidí z Oculus Studios (včetně týmu fitness titulu Supernatural). Meta však tvrdí, že současně nabírá téměř 500 nových pozic v oblasti AR/MR a že Ray‑Ban smart brýle „překonávají očekávání“.
Mobil Motorola Razr 2025 přichází ve třech verzích, špičková Ultra nabízí Snapdragon 8 Elite, 165 Hz displej a trojici 50 Mpx snímačů. Předobjednávky startují 7. května, prodej 15. května.
Nintendo Switch 2 s dokovaným 4K/60 fps (a až 120 fps v 1080p) zmizel z předobjednávek během hodin; oficiální uvedení 5. června za 449 USD.
LG zpřístupnilo aplikaci Xbox Cloud Gaming na chytrých TV s webOS 24+, což v 25 zemích promění televizi v plnohodnotnou herní konzoli – stačí předplatné Game Pass Ultimate a Bluetooth ovladač.
MetaMask znovu varovalo uživatele před falešnými peněženkami a podvodnými tokeny – firma zdůrazňuje, že nemá žádný oficiální token a jakékoli airdropy lákají k phishingu.
Wall Street - Akcie Truth Social (DJT) se sice loni bouřlivě uvedly na Nasdaq, ale podle Fortune už klíčoví insideři postupně odprodávají podíly – CFO Phillip Juhan prodal akcie za 1,9 mil. USD, což při nízké likviditě tlačí kurz dolů.
Politika a regulace - Bílý dům vydal dvě nová memoranda, jež federálním úřadům poprvé stanovují minimální standardy pro nákup a správu systémů umělé inteligence – mj. vyžadují „proof‑of‑concept“ před plným nasazením a povinné auditní logy.
Tak a to je pro první květnový týden všechno!
Vše nejlepší do nového týdne přeje
Patrick Zandl
PS: Email byl odeslán na 4049 odběratelů.
💡 Workshop o AI ve firmách
Ukazuji firmám, jakou změnu pro ně představuje AI. Workshop AI ve firmách je společná interaktivní SWOT analýza toho, jak na vaši firmu dopadne umělá inteligence. Pojďme se nad tím společně zamyslet…
