


#88 Deepseek a rozmetání Hvězdné brány
Nová čínská AI pořádně zamávala trhem. Přestanou se kvůli Deepseeku prodávat procesory Nvidia, nebo proč se vypařil bilion dolarů z trhu? A jak je to s Trumpovým půlbilionovým projektem Stargate?

Dobrý den,
vítejte u Patrickova newsletteru. Bude zase hlavně o AI novinkách, protože je na AI scéně pěkně horko! A to jsem původně chtěl přinést obsáhlý článek o tom, jak s pomocí AI programovat, protože jsem to pro vás důkladně otestoval. Ale to si necháme na příště.
🤖 Drobné AI novinky na začátek
První agent od OpenAI se jmenuje Operator. Dokáže spustit prohlížeč a plnit úkoly "vaším jménem". Operátora pohání nová verze 4o vyladěná pro použití na počítači. Pokud chcete, můžete od agenta převzít řízení, nebo vám dá vědět, když bude potřebovat vaši pomoc (například při přihlašování na nějakou webovou stránku). V současné době je Operator k dispozici pouze předplatitelům ChatGPT Pro (200 USD/m) v USA, jedná se o výzkumný náhled. Není zrovna nejrychlejší, ještě to trochu práce chce. Zde je podrobný přehled schopností Operátora.
ChatGPT Canvas dostal dlouho požadovanou aktualizaci od OpenAI (a něco, co mohou používat předplatetelé s tarifem Plus). Nyní vykresluje HTML a React Code a navíc pracuje s modelem o1 od OpenAI. Má nás tak nechat zapomenout na Claude Artifacts. Ty by oprášit potřebovaly.
Claude se zlepšuje v citování zdrojů. Nová funkce rozhraní API Anthropic, Citations, vám s přesností na slovo řekne, na které části vašich souborů PDF a dokumentů se Claude při své odpovědi odvolával. Je k dispozici v modelech Claude 3.5.
💡 Workshop o AI ve firmách
Ukazuji firmám, jakou změnu pro ně představuje AI. Workshop AI ve firmách je společná interaktivní SWOT analýza toho, jak na vaši firmu dopadne umělá inteligence. Pojďme se nad tím společně zamyslet…

🐟 Deepseek jako čínský Sputnik
Asi jste to zaznamenali. Čínská firma Deepseek vydala své nové AI modely a z akciového trhu amerických technologických firem se v tu ránu vyfouklo bilion dolarů. Akcie Nvidia a Broadcomu, dvou veřejně obchodovatelných firem závislých na úspěchu prodeje AI čipů. poklesly za den o 17 procent (v pondělí) a za úterý se kurz nevzpamatoval, spíše to vypadá, že se stabilizuje.
Něco málo si k tomu řekněme:
Platí pravidlo žádných prudkých pohybů. Jestli máte akcie, zatím se jich nezbavujte.
Tento článek jsem od soboty přepsal třikrát a rozhodl se, že z něj udělám jen velmi malý teaser. Situace se totiž stále neusadila a není úplně jasné, co je pravda, náhoda a co třend.
Co se vlastně stalo? Čínská firma Deepseek vydala před vánoci druhou generaci svého AI LLM. Už to bylo velký. Teď vydala další a uvolnila webovou verzi svého modelu jako open source ke stažení. A byla z toho právě ta bomba na trhu, kdy se z toho všichni vzpamatovávají a přemýšlejí, co to znamená a jak to všechno mění…
Takže si pojďme dát rychlou časovou osu s komentáři:
Prosinec 2024
DeepSeek vydává model DeepSeek-V3
Model využívá architekturu “mixture of experts” pro efektivnější využití parametrů
Reakce: Model je označen za významný pokrok v open-source AI (ITOnline). Ale jinak je zatím klid.
20. ledna 2025
DeepSeek vydává model DeepSeek-R1
R1 je zaměřen na pokročilé uvažování a řešení komplexních úloh
Reakce:
Model je označen za průlomový, srovnatelný s OpenAI o1
Aplikace DeepSeek se stává nejstahovanější v App Store (TechCrunch)
24. ledna 2025
Vychází najevo, že DeepSeek údajně vyvinul R1 za pouhých 6 milionů dolarů (je to trochu dezinfo, tolik stál čistě procesorový čas na trénování, není v tom práce, pokusy, ladění atd)
Reakce:
Pochybnosti o pravdivosti tvrzení mezi některými odborníky
Obavy investorů z možného narušení dominance amerických technologických firem (Livescience.com)
26.-27. ledna 2025
Dramatický propad akcií technologických firem
Nvidia ztrácí 17% hodnoty, což představuje rekordní jednodenní ztrátu 593 miliard dolarů
Celkově je z trhu smazáno přibližně 1 bilion dolarů hodnoty (Evrimagaci)
27. ledna 2025
DeepSeek vydává model Janus-Pro-7B pro generování obrázků
Model údajně překonává DALL-E 3 a Stable Diffusion v některých benchmarcích
Reakce:
Další šok pro trh a konkurenci
Rostoucí uznání DeepSeeku jako vážného konkurenta v globálním AI závodě (ObserverVoice)
28. ledna 2025
Pokračující diskuse o dopadu DeepSeeku na globální AI trh
Někteří experti vyzývají k opatrnosti při hodnocení tvrzení DeepSeeku
Rostoucí debata o budoucnosti AI vývoje a globální konkurenci v této oblasti (Mickryan, FinancialExpress
Co je hlavní překvapení, zádrhel a ten Sputnik efekt, ze kterého si Amerika (a především US technologické trhy) sedly na zadek?
Na jednu stranu náklady. Na druhou stranu obrovská kvalita výstupu.
Náklady: jak to za ty peníze udělali?
Nejpozoruhodnější na DeepSeek-V3 však byla asi jeho cena. Společnost DeepSeek uvedla, že V3 trénovala přibližně dva měsíce na clusteru s 2 048 grafickými procesory, což představuje celkem 2,8 milionu GPU-hodin. Za předpokladu, že pronájem GPU stojí 2 dolary za hodinu, vychází to na přibližně 5,6 milionu dolarů nákladů na trénink.
Pro srovnání, společnost Meta trénovala modely Llama 3 na clusteru s 16 000 GPU. Odborníci z oboru odhadují, že trénink největšího modelu Llama 3.1, který má 405 miliard parametrů, zabral přibližně 30 milionů hodin na GPU. Jinými slovy, trénink modelu Llama vyžadoval přibližně desetkrát větší výpočetní výkon než trénink modelu V3. A není zřejmé, že by Llama byl lepší model než V3.
Jasně, v tom dokument Deepseeku to není napsané zcela přesně a je velmi pravděpodobné, že ve skutečnosti to stálo o pár nikláků více za nejrůznější testy a práce kolem toho, ale ten propad ceny na desetinu je ohromující. Za to nemůže jen faktor "čínské ceny", tedy nižších nákladů v Číně, je za tím několik technologických průlomů. Je tu celá řada pokročilých algoritmů, jako třeba Multi-head Latent Attention (MLA). Ta umožňuje efektivnější inferenci díky kompresi klíčových hodnot do latentního vektoru. Česky řečeno MLA snižuje nároky na paměť během generování textu, což se projevuje ve výrazně snížených nárocích na hardware. Ale majstrštyk byl způsob, jakým tým obešel embargo na vývoz špičkových procesorů Nvidia H100. Trénink místo nich probíhal na pomalejší verzi H800 s pomalejší pamětí. A tak si deepseek napsal vlastní ovladače paměti a tím z handicapu udělal výhodu.
DeepSeek také využívá optimalizované CUDA kernely pro zvýšení rychlosti tréninku i inference. Tyto kernely jsou specificky navrženy a upraveny pro potřeby modelů DeepSeek, aby maximalizovaly využití výpočetního výkonu GPU.
Takových přistupů a zlepšení měl za sebou Deepseek celou řadu a tím také vznikla ta technologická panika. Zjednodušeně řečeno, když vám na trénink nejpokročilejší AI stačí dvě tisícovky procesorů Nvidia, na co si pak kdo bude kupovat ty hromady procesorů, které Nvidia musí prodat, aby naplnila očekávání akcionářů? A to byl důvod, proč se akcie Nvidia a také třeba Broadcomu sesunuly v pondělí dolů a z tržní hodnoty amerických firem zmizelo 1000 miliard dolarů.
A ceny API pro zákazníky?
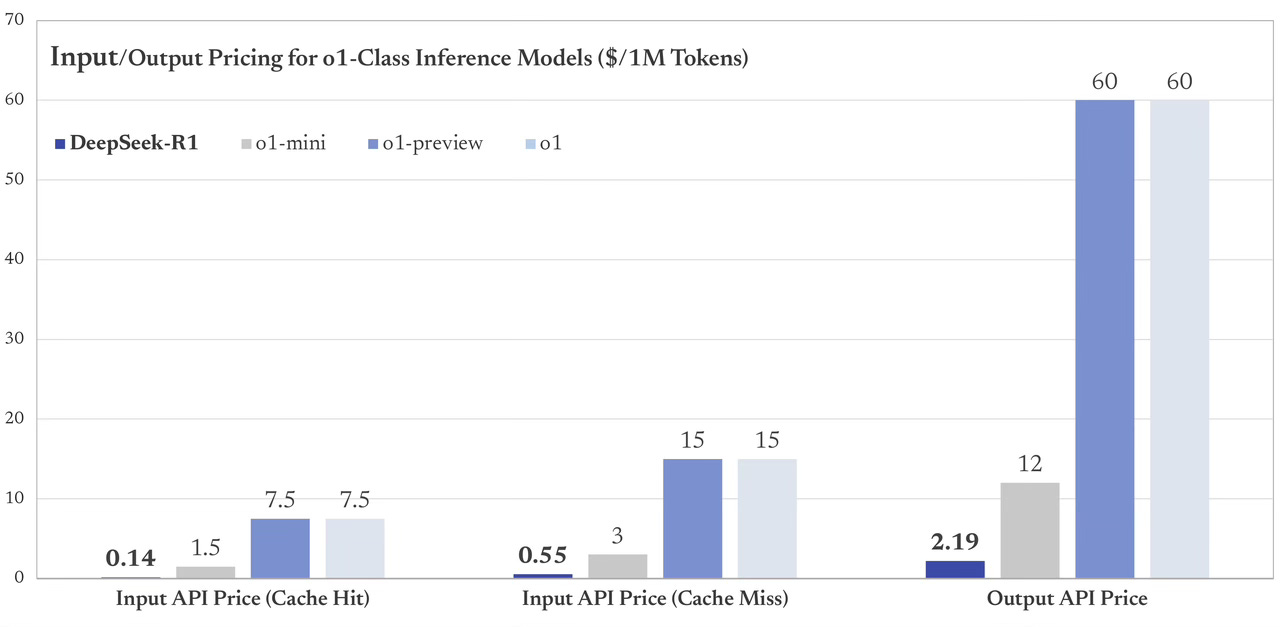
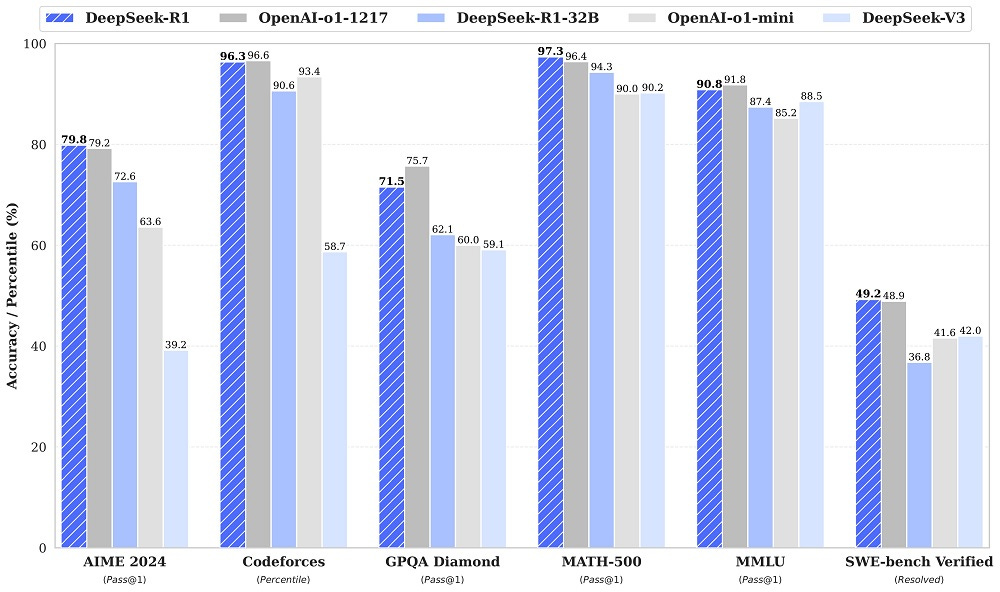
Co kvalita?
Zjednodušeně řečeno jsou výstupy Deepseek-R1 plus mínus na stejné úrovni, jako o1 model. Graf klidně přeskočte, jestli mi věříte, ale fakultativně si jej okomentujme. Podívejme se zejména na testy, které se považují za extrémně těžké: MATH 500 (což je náhodně vybraných 500 úloh z celé testovací sady), AIME 2024 (super těžké soutěžní matematické úlohy), Codeforces (soutěžní kód představený v o3) a SWE-bench Verified (Vylepšené rozdělení datové sady OpenAI). Překonat dvojici GPT-4o a Claude 3.5 dohromady, a to s takovým náskokem, je vzácné. A ano, funguje Deepseek dobře i v češtině, i když plynulost textu je podle mě lepší jak u o1 tak u Claude, ale nic, na čem byste museli bazírovat.
Co s tím dále?
Já budu situaci pozorovat, k Deepseek se chystám sepsat obsáhlejší povídání, kde si to rozebereme. Pro nás jsou ale podstatné následující poznatky - vezmu to stručně a v bodech:
v AI stále ještě není všechno rozdáno. Tým Deepseeku je kolem 150 lidí, naprostá většina jsou mlaďoši, kteří před dvěmi lety dodělali doktorát na nějaké prestižní čínské univerzitě. A zatřásli světem.
V AI je stále ještě prostor pro chytrost a motivovaný tým
Cena je zásadní měřítko, Deepseek shodil ceny za používání AI modelů v Číně na třicetinu a podobně zatřese cenami všude jinde. Jejich API jede podle OpenAI, takže přepojení na ně a využívání velmi kvalitního AI za nižší cenu brání jen málo co
ale pořád je to Čína: data putují do Číny, věřte si tomu, kdo a co chcete, ale čínské zákony jsou jasné a neúprosné, stejně jako licenční podmínky, které říkají, že mohou všechno.
zatím to nevypadá, že by mobilní apka do Číny posílala nezbytně více věcí, než maximum, ale stejně: pokud chcete experimentovat na mobilu, dělejte to přes web. Navíc Deepseek teď má kapacitní problémy a přetížené servery, nebudete z něj mít tak dobrý dojem, jak dobrý skutečně je.
je vidět, že velká část práce je dnes ve směru agentů, tedy vyměny dat mezi LLM a vnějším světem. Deepseek nemá žádná rozhraní a napojení do vnějšího světa krom přístupu na web. A nemá ani podpůrné režimy jako Canvas či Artifact.
Jedno podstatné sdělení zůstává pro EU: pokusit se regulovat AI bylo ... zajímavý, odvážný, ba revoluční nápad. Jenže se bude muset změnit. Deepseek je totiž opensource a dá se předpokládat, že kvůli jeho kvalitám na něj přejdou všichni, co opensource potřebují. Jenže nebudou moci dodržet regulaci EU týkající se jasné definice trénovacích dat. Deepseek do své AI něco nasypal, moc není jasné, co (část trénoval vůči AI od OpenAI, což jeho chat bezelstně přiznává) - a jak by se z toho udělala věrohodná definice původu obsahu, mi jasné není. Takže jakkoliv je důvod té regulace odůvodněný, všichni se zřejmě smíří s tím, že to funguje a funguje to dobře, čert vem, kde vazli data. Akorát se toho nemáte ptát v Číně na Náměstí nebeského něčeho, ale na staženém modelu už můžete dodat i to, že jde o klid.
Deepseek r1 je působivý model, zejména s ohledem na to, co jsou schopni nabídnout za cenu. My samozřejmě dodáme mnohem lepší modely a také je to legitimně povzbuzující mít nového konkurenta! vytáhneme nějaké verze. Ale hlavně jsme nadšeni, že můžeme pokračovat v realizaci našeho výzkumného plánu a věříme, že více výpočetní techniky je nyní důležitější než kdykoli předtím, abychom uspěli v našem poslání. Svět bude chtít používat hodně AI a opravdu bude docela ohromen přicházejícími modely nové generace. Těšíme se, až vám všem přineseme AGI a další. - 28.1.2025, tweet Sama Altmana, šéfa OpenAI
🚀 Projekt Stargate čili Hvězdná brána
Společnosti OpenAI, SoftBank, Oracle a MGX oznámily plán investovat v příštích 4 letech 500 miliard dolarů do datových center umělé inteligence v USA, z toho 100 miliard dolarů „okamžitě“. To vyvolalo řadu otázek. Tak především ani OpenAI, ani Oracle, ani SoftBank ve skutečnosti na nic takového nemají. Minulou středu Sam Altman zaměstnancům zřejmě sdělil, že OpenAI a SoftBank vyčlení každá pouze 19 miliard dolarů. O společnosti Oracle zatím nepadlo ani slovo, ale její finanční výtlak je sotva poloviční. A Elon Musk prohlásil: „Oni ty peníze ve skutečnosti nemají. SoftBank má zajištěno mnohem méně než 10 miliard dolarů. Mám to z dobrého zdroje." Musk sám ovšem nijak dobrý zdroj není.
Slušných 80 miliard dolarů do výstavby datových center zřejmě opravdu nějakou formou investuje Microsoft, ale nedělá to proto, aby potěšil Donalda Trumpa, ale aby zajistil kapacity pro svoje Azure služby.
A MGX, což je součást systému státních investičních fondů Spojených arabských emirátů? To prý cílí na 100 miliard dolarů. Ale to je tak všechno, co se ví. Kdo projekt Stargate řídí a jaké jsou skutečné cíle, se zatím neví. Donald Trump značil projekt za “monumentální počin” a zdůraznil jeho potenciál v technologické rivalitě s Čínou, přislíbil urychlit povolení a schvalovací procesy.
Na 500 miliard strategické investice, která má být klíčový nástroj pro udržení technologické dominance USA v oblasti umělé inteligence, je to dosti málo informací...
✨ Zajímavé nové služby
Firecut AI - AI videoeditor, který vám pomůže udělat z vašeho videa něco koukatelného.
Outfit.fm - fotky oblečení se pomocí AI navléknou na postavu, ideální na produktové fotky oblečení.
Arcade Software - vytvořte jednoduše demo vašeho software
Juno - 10x lepší datová věda díky psaní, úpravám a automatickému ladění kódu za pochodu.
Tip na závěr: jestli jste zákazník T-Mobile, můžete dostat předplatné Perplexity Pro na rok zdarma. Perplexity Pro si aktivujte v aplikaci Můj T-Mobile. Využijte to, Perplexity vám nehledá stránky, ale přímo informace a stojí to za to!
Tak ať se i váš business neprobere do nového dne s čínským konkurentem hluboko v zádech.
Patrick Zandl
PS: Newsletter byl rozeslán na 3527 adres.
🤫 Postupy a návody k využití AI ode mne:
AI pro rodiče školáků je zdarma ebook, který přináší řadu postupů a rad, jak používat AI ve vzdělávání s dětmi.
AI už pomůže s psaním beletrie - jak použít AI pro psaní knih a příběhů
Jak pomocí umělé inteligence nastudovat téma a napsat lepší článek do novin
kompletní rubrika AI představující to, jak AI funguje a co umí.
Jak to vidíte s robopsychologií (ve významu dle Asimova)? Je už čas zralý na to, aby se AI (tedy konkrétně LLM) začly zkoumat podobně, jako lidská mysl? Tj. zjišťovat, zda má nějaké vlastní motivace, které jsou ale skryty pod vrstvami pěkných odpovědí?